- gf24240 的博客
《梦溪笔谈·C++》卷四十六:图之图的存储和遍历
-
 gf24240
LV 10
@
2026-4-17 23:02:18
gf24240
LV 10
@
2026-4-17 23:02:18
前言
图论真是枯燥我还跳过了树,好在已经过来了。
前面的内容比较简单,所以会短邑点
图的存储
图的存储有三种方式:
- 邻接矩阵
- 邻接链表
- 链式前向星
其中,我们最常用的是邻接链表。
记住这个图:
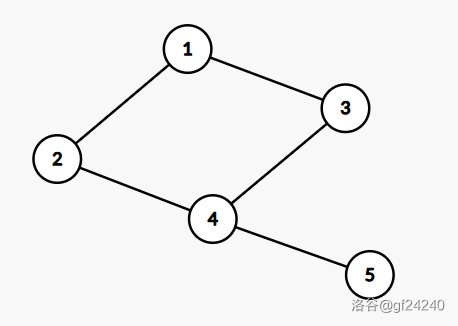
下面会用这个图来举例。
邻接矩阵
定义一个二维数组 g,其中 g[u][v] 表示节点 和节点 是否相连。如下:
| 节点 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | ||
| 2 | 0 | 1 | |||
| 3 | 1 | 0 | 0 | ||
| 4 | 0 | 1 | 0 | ||
| 5 | 0 | 1 | 0 |
其中,如果边有权值,可以设为权值而不是 。
- 添加边:要在 添加一条边,只需要把
g[u][v]设为 或权值。 - 删除边:要删除 之间的边,只需要把
g[u][v]设为 。 - 判断边:判断 是否有边,只需要查找
g[u][v] || g[v][u]。 - 遍历边:枚举所有点,判断是否与 相连。
优点
删边、添边极快,容易理解。
缺点
内存占用大()。
遍历时间 。
邻接链表最常用
本质上是定义 条链表,第 条链表上是与 相连的点。
但是使用链表极其繁琐,而 vector 正好可以解决这个问题。如表:
| 节点 | 与 | 它 | 相连 | 的 | 点 |
|---|---|---|---|---|---|
| 1 | 2 | 3 | / | ||
| 2 | 1 | 4 | |||
| 3 | |||||
| 4 | 2 | 3 | |||
| 5 | 4 | / | |||
定义 vector <int> g[N]( 是常量,表示点数 的最大值)。内容就和上表是一样的。
- 添加边:要添加 边,只需要
g[u].push_back(v)。 - 删除边:要删除 边,需要枚举 的所有边,如果有 ,就删除(
g[u].erase(g[u].begin() + k))。 - 查找边:遍历 的所有边,判断是否有 与它相连。
- 遍历边:循环遍历
g[u]。
优点
内存占用小,添加边容易。
缺点
删边复杂。
链式前向星
定义一个 head[N]、edge[N][3](或 {u,v,next}edge[N])。
head[u] 表示与 相连的第一条边在 edge 的位置。edge[id].u 表示这一条边的一段,edge[id].v 则是另一段,edge[id].next 表示 edge[id].u 的下一条边在 edge 的边号。
如表:
| 节点 | head |
|---|---|
| 1 | |
| 2 | 3 |
| 3 | 5 |
| 4 | 7 |
| 5 | 10 |
| 边号 | |||
|---|---|---|---|
| 1 | 2 | ||
| 2 | 1 | 3 | -1 |
| 3 | 2 | 1 | 4 |
| 4 | 4 | -1 | |
| 5 | 3 | 1 | 6 |
| 6 | 4 | -1 | |
| 7 | 4 | 2 | 8 |
| 8 | 3 | 9 | |
| 9 | 4 | 5 | -1 |
| 10 | 5 | 4 |