- gf24240 的博客
《梦溪笔谈·笔记》2025/8/2~3:数论·素数&GCD
-
 gf24240
LV 10
@
2025-8-3 20:06:42
gf24240
LV 10
@
2025-8-3 20:06:42
前言
这一块就有好讲的了。如果有问题请指出。
目录:
素数 [1]
这是很大很重要又很简单的一部分(算简单的了)。
定义: 素数(又称质数)是指除了 和本身之外没有其他因数的数。例如 等。注意: 不是素数。
素数的判定 [2]
首先,要看素数的定义:
定义: 素数(又称质数)是指除了 和本身之外没有其他因数的数。例如 等。注意: 不是素数。
因此,可以设计一个算法,枚举从 到 的数字,检查是否能整除 。如果可以,则说明 是合数。如果都没有,则说明 为素数。代码如下:
bool isp(int n)
{
if (n < 2)return 0;
for (int i = 2; i < n; i++)
{
if (n % i == 0)return 0;
}
return 1;
}
需要注意 不是素数。
时间复杂度: 。但是这并不高效(线性筛在这点时间能求 个数,这个只能求 个数你好意思吗)。
这样考虑: 的因子都是成对出现的(自动忽略平方数),而且每一对都有较大和较小。只需要在 的一半中找到 的较小的因子就好了。代码:
bool isp(int n)
{
if (n < 2)return 0;
int a = n / 2;
for (int i = 2; i <= a; i++)
{
if (n % i == 0)return 0;
}
return 1;
}
这样就优化到了 。但是还不够高效。
假设 不是平方数。因为 的因子都是成对出现的,所以我们可以把 的因子分为 部分:
- 较小的因子;
- 较大的因子。
但是“较”是不确定的,需要求解。设 为“较小的因子”中最大的,那么 ,且 十分接近 。设 为 的因子中比 更大的因子。假设 也小于 ,那么 一定会小于 。但这与 “ 为‘较小的因子’中最大的”冲突。
这下“较小”和“较大”的分解线就明确了: 。举一个简单的例子。这是 的所有因子:
$$1 \times 100 \\ 2 \times 50 \\ 4 \times 25 \\ 5 \times 20 \\ 10 \times 10 \\ 20 \times 5 \\ 25 \times 4 \\ 50 \times 2 \\ 100 \times 1$$可以发现, 就是 的因子中“较小的因子”的最大的。如果 没有“较小的因子”,那么 也不会有“较大的因子”。于是可以优化判断素数的代码,只需要循环到 。时间复杂度: 。代码:
bool isp(int n)
{
if (n < 2)return 0;
int a = sqrt(n);
for (int i = 2; i <= a; i++)
{
if (n % i == 0)return 0;
}
return 1;
}
还可以继续优化。先判断是否是偶数,后面只循环奇数。时间复杂度: 。代码:
bool isp(int n)
{
if (n == 2)return 1;
if (n < 2 || n % 2 == 0)return 0;
int a = sqrt(n);
for (int i = 3; i <= a; i += 2)
{
if (n % i == 0)return 0;
}
return 1;
}
其实还可以继续优化,但是会非常麻烦。理想最优解:只循环素数。
素数的筛法 [3]
概念: 利用某个基数,它的倍数都是合数,所以都筛掉。
素数筛1-普通筛
按照上面的方法。用两层循环模拟基数和倍数。注意不要出界。时间复杂度: (因为倍数是倍增的)。代码:
int n, pre[N], top;
bool isp[N];
void make()
{
isp[0] = isp[1] = 1;
for (int i = 2; i <= n; i++)
{
if (!isp[i])pre[++top] = i;
for (int j = i; j <= n; j += i)
{
isp[j] = 1;
}
}
}
素数筛2-埃氏筛
埃氏筛是对于普通筛的优化。对于普通筛有两种优化方式。
埃氏筛A
- 例如 的倍数肯定已经被 的倍数筛过了,所以可以只筛素数。
- 由于前 ~ 已经被筛过了,所以 循环可以从 开始。
时间复杂度: 。代码:
int n, pre[N], top;
bool isp[N];
void make()
{
isp[0] = isp[1] = 1;//这里为了方便实际上标记的是合数
for (int i = 2; i <= n; i++)
{
if (!isp[i])
{
pre[++top] = i;
for (int j = i * i; j <= n; j += i)
{
isp[j] = 1;
}
}
}
}
埃氏筛B
不再是枚举基数了,而是枚举倍数。对基数的枚举在 pre 和 循环中。简单来说:用 循环枚举倍数, 循环在 pre[] 中枚举基数。时间复杂度: 。代码:
int n, pre[N], top;
bool isp[N];
void make()
{
isp[0] = isp[1] = 1;//这里为了方便实际上标记的是合数
for (int i = 2; i <= n; i++)
{
if (!isp[i])pre[++top] = i;
for (int j = 1; j <= top; j++)
{
if (i * pre[j] > n)break;//防止出界
isp[i * pre[j]] = 1;
}
}
}
可以发现埃氏筛已经很快了,但是还是有重复的筛选。
埃氏筛Aa
这个埃氏筛 Aa 是对埃氏筛的一点没啥用的优化。如果不用存储素数的话,对于外层循环可以只枚举到 。
素数筛3-线性筛(欧拉筛)
线性筛(又称欧拉筛)是对埃氏筛 B 的优化。
线性筛的结论是保证每个数 一定只能在他的最小素数因素的时候被筛掉例如 $24=2 \times 2 \times 2 \times 3=2 \times 12=3 \times 8$;
如果没有 if(i%prime[j]==0)break; 这句,那么当 时候,根据 vis[iprime[j]] ,当 时候先筛掉 这个数,然后当 时候继续筛 这个数,然后筛 ......
其中 这个数在 即 时候又会被重复筛一次; 这个数在 即 时候又会被重复筛一次......
因为 if(i%prime[j]==0)break; 上述魔法语句的存在,当 时候就会 break ,那么 就不会在 的时候被筛掉,而是一定只会在 时候,即 的时候被筛掉,所以当 的时候,都筛不到 这样就保证了,每一个数,有且仅有一次被筛到,而且一定是被它的最小质因数筛到,所以 个数就最多是筛 次,时间复杂度优化到了 。
原文链接:https://www.bcoi.cn/discuss/661faa104291ba6dd5355eff#1713606736407
原文的原文的链接:https://blog.csdn.net/Yuki_fx/article/details/115103663
代码:
int n, pre[N], top;
bool isp[N];
void make()
{
isp[0] = isp[1] = 1;//这里为了方便实际上标记的是合数
for (int i = 2; i <= n; i++)
{
if (!isp[i])pre[++top] = i;
for (int j = 1; j <= top; j++)
{
if (i * pre[j] > n)break;//防止出界
isp[i * pre[j]] = 1;
if (i % pre[j] == 0)break;//这步是魔法
}
}
}
如果用 vector 会简洁一些,但是时间可能会更长。
int n;
bool isp[N];
vector <int> pre;
void make()
{
isp[0] = isp[1] = 1;//这里为了方便实际上标记的是合数
for (int i = 2; i <= n; i++)
{
if (!isp[i])pre.push_back(i);
for (auto j : pre)
{
if (i * j > n)break;//防止出界
isp[i * j = 1;
if (i % j == 0)break;//这步是魔法
}
}
}
GCD [4]
这一块是又大又重要又很难的一块。你以为这一块只有最大公约数,实际上多得多。
GCD&LCM [5]
约数,就是因数。
公约数,就是几个数共有的约数。
最大公约数(GCD),就是几个数的共约数中最大的。
倍数、公倍数、最小公倍数(LCM)也差不多。
求 GCD 的方法
有两种方法:
- 辗转相除法(欧几里得算法);
- 二进制算法;
辗转相除法: 证明略。
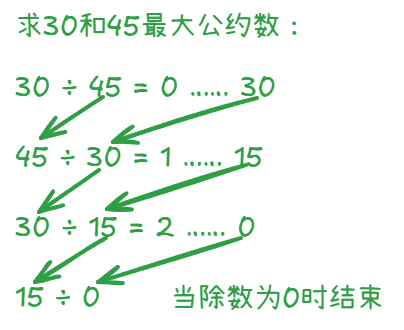
这比小学学的短除法快多了。很快可以发现,这可以用递归来实现。核心代码:
int gcd(int n, int m)
{
if (m == 0)return n;
return gcd(m, n % m);
}
二进制算法: 这是提高组的内容。
可以通过不断去除因子 来降低常数。对于 ,分五种情况:
- 若 ,则 。
- 若 均为偶数, 。
- 若 为偶数, 为奇数, 。
- 若 为奇数, 为偶数, 。
- 若 均为奇数, 。
需要注意一些问题: 造成负数、运算符优先级等。代码(递归):
int gcd(int x, int y)
{
if (y == 0)return x;
if (x == y)return x;
if ((x & 1) == 0 && (y & 1) == 0)return gcd(x >> 1, y >> 1) << 1;
if ((x & 1) == 1 && (y & 1) == 0)return gcd(x, y >> 1);
if ((x & 1) == 0 && (y & 1) == 1)return gcd(x >> 1, y);
if ((x & 1) == 1 && (y & 1) == 1)
{
if (x > y)return gcd(x - y, y);
else return gcd(y - x, x);
}
}
实际上辗转相除法和二进制 GCD 算法的时间复杂度都是 ,只是二进制 GCD 的位运算比辗转相除法的 % 运算更快。
求 LCM 的方法
求 LCM 也有两种方法:
- 公式法。
- 倍增法。
公式法: 只需要一点小小的推理。 我们知道: 和 的最大公约数和最小公倍数的积等于 和 的积。那么:
$$gcd(a,b) \times lcm(a,b) = a \times b \\ lcm(a,b) = a \times b \div gcd(a,b) \\$$所以可以根据这个公式来推导 LCM 。时间复杂度: 。代码:
int lcm(int a, int b)
{
return a * b / gcd(a, b);
}
倍增法: 倍增较大数,如果能被较小数整除,则为最小公倍数。时间复杂度: 。代码:
int lcm(int a, int b)
{
if (a < b)a = a ^ b, b = a ^ b, a = a ^ b;//相当于swap(a,b); ,保证a>b
int i = 1;
while (a * i % b != 0)
{
i++;
}
return a * i;
}
远不如公式法。
扩展欧几里得算法 [6]
扩展欧几里得算法( ExGCD ),是用于根据一组 求 和 使 成立的一组解。证明:
设 $a \times x_0 + b \times y_0 = \gcd(a, b) \\ b \times x_1 + (a \mod b) \times y_1 = \gcd(b, a \mod b)$ 。
根据欧几里得算法,
所以 $a \times x_0 + b \times y_0 = b \times x_1 + (a \mod b) \times y_1$
而 $a \mod b = a - (\lfloor \frac{a}{b} \rfloor \times b)$
所以 $a \times x_0 + b \times y_0 = b \times x_1 + (a - \lfloor \frac{a}{b} \rfloor \times b) \times y_1$
去括号,得 $a \times x_0 + b \times y_0 = b \times x_1 + a \times y_1 - \lfloor \frac{a}{b} \rfloor \times b \times y_1$
合并同类项,得 $a \times x_0 + b \times y_0 = a \times y_1 + b \times(x_1 - \lfloor \frac{a}{b} \rfloor \times y_1)$
因为 ,所以左右两边同时除以 和 ,得
$$x_0 = y_1 \\ y_0 = x_1 - \lfloor \frac{a}{b} \rfloor \times y_1$$利用引用技术,回溯时计算就好了。时间复杂度和欧几里得算法相同。代码:
int gcd(int a, int b, int& x, int& y)
{
if (b == 0)
{
x = 1;
y = 0;
return a;
}
int ret = gcd(b, a % b, x, y);
int x1 = x;
x = y;
y = x1 - (a / b) * y;
return ret;
}
丢番图方程 [7]
丢番图方程,是形如这样的二元一次方程: 。
补充:二元一次方程的定义
- 含有两个未知数;
- 含未知数的项的次数为一;
- 是整式;
- 是等式; (应该没了)
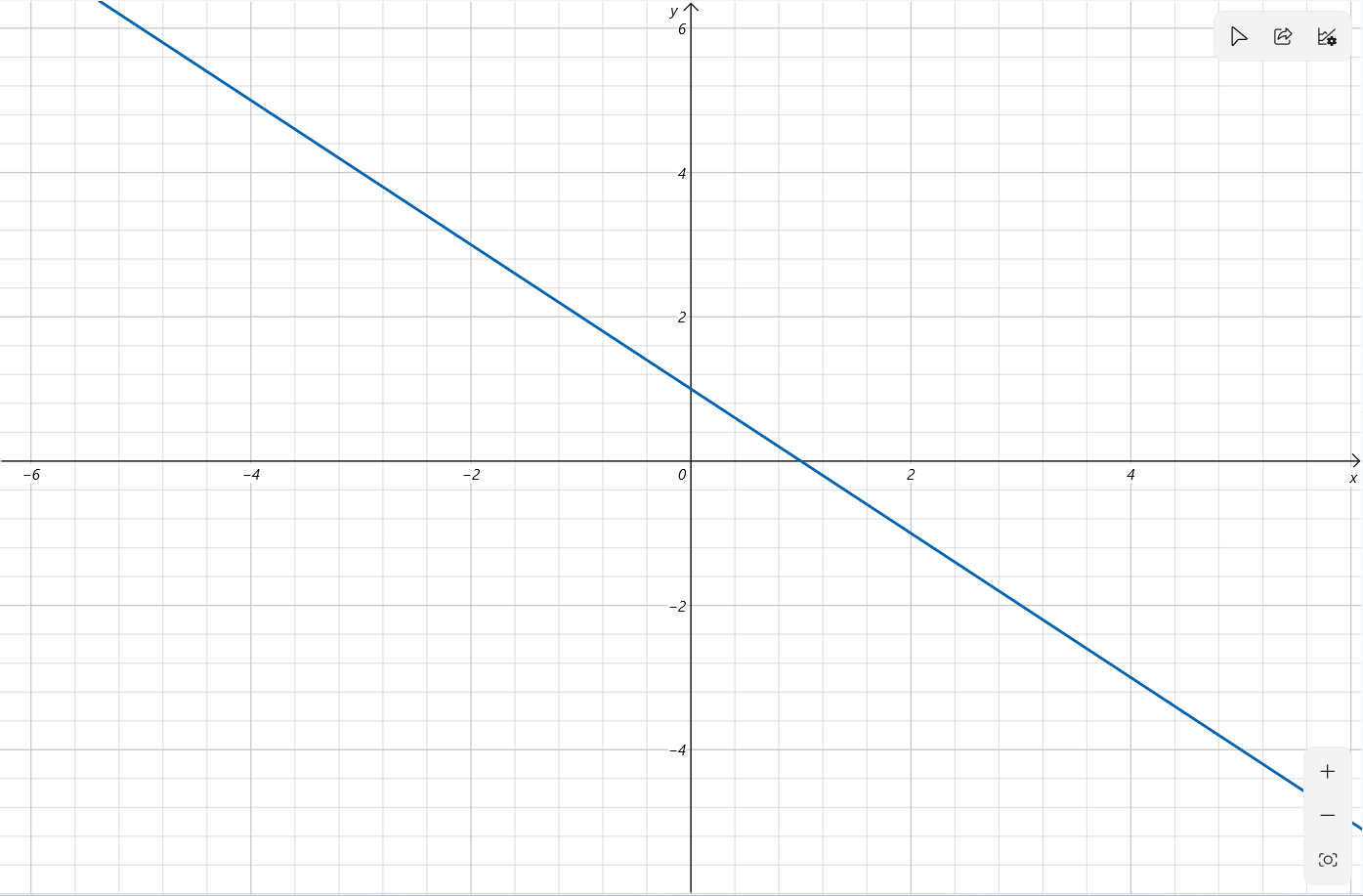
二元一次方程的函数图像为一条直线。例如这是 的图像:
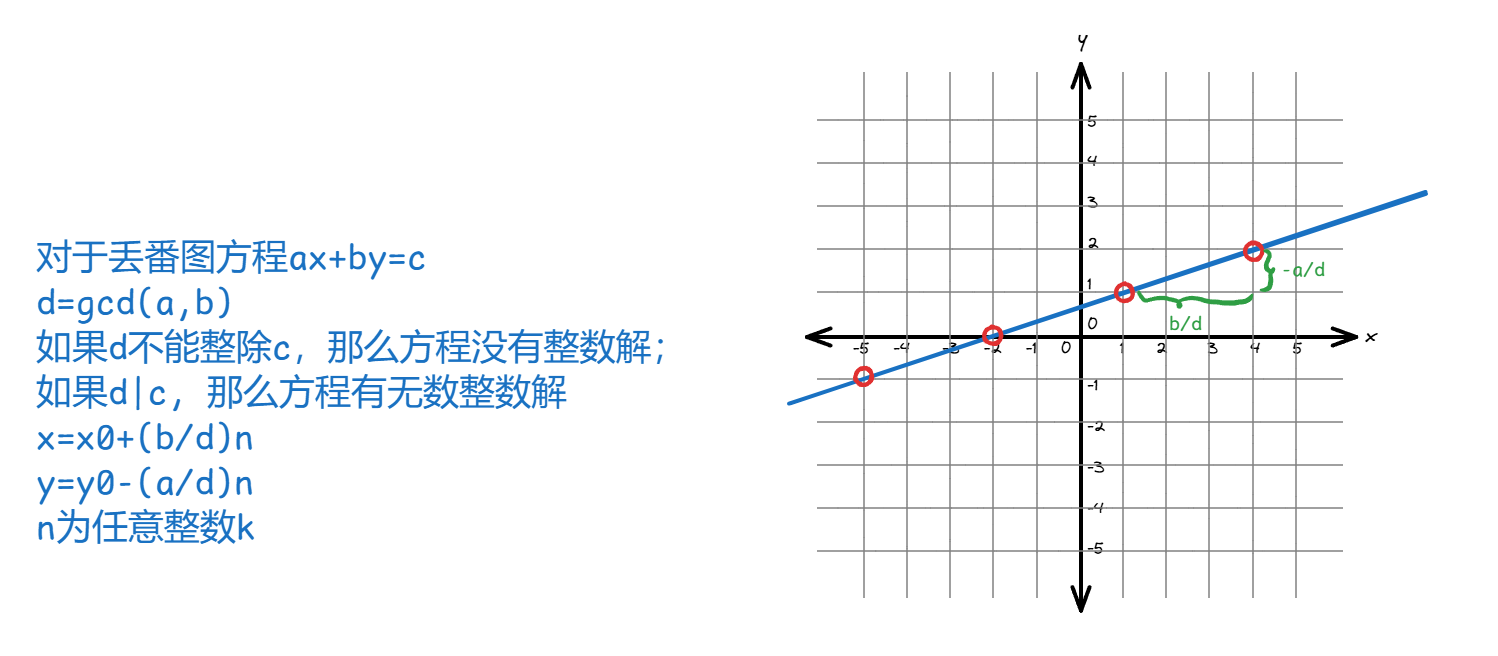
裴蜀定理 [8]
裴蜀定理,又称贝祖定理(Bézout's lemma)、贝祖等式(Bézout's identity)。是一个关于最大公约数的定理。 来源: https://oi-wiki.org/math/number-theory/bezouts/
裴蜀定理的内容是: 对于整数 和 , ,满足 ,且存在整数 和 使得 。
证明:略。
斐波那契数列 [9]
想不到吧!还有一块。 其实这部分不多。
定义: 斐波那契数列。又称黄金分割数列。它的前两项为 ,剩下每一项为前两项之和。这是斐波那契数列的前几项: 。
递推方程: f[i] = f[i - 1] + f[i - 2] 。
通项式:
$$F(n) = \frac{\sqrt{5}}{5} × [(\frac{1+\sqrt{5}}{2})^n-(\frac{1-\sqrt{5}}{2})^n]$$性质:
- 前 n 项的和 = a[1]+a[2]+......+a[n] =
2a[n]+a[n-1]=a[n+2]-1 - 奇数项和=a1+a3......+a[2n-1]=
a[2*n] - 偶数项和=a2+......+a[2n]=
a[2n+1]-1 - 平方和=a1^2+a2^2+......+an^2=
a[n]*a[n-1] - 中项:3a[i]=
a[i-2]+a[i+2]